(更新Roofline图)在笔记本市场中,Intel Ultra系列和AMD 8000系列不约而同的加入了集成NPU作为卖点(甚至对于AMD而言,是其7000系到8000的几乎唯一变化),各路数码新闻中鼓吹最多的便是所谓“AIPC”概念,但却往往对其NPU的具体用法语焉不详,或者将一些实际使用核显进行的推理归功于NPU。
由于本人近日购入了Intel Core Ultra CPU的笔记本,外加科研需要,对其集成NPU进行了一些调研。
省流:通常跑AI推理的实用性不如核显,目前仅支持静态shape的模型,因此无法做LLM推理,通常只做AI抠图这类简单任务。目前最大的用途是Win11自带的“工作室”效果功能,包含摄像头背景虚化、眼神接触、自动缩放取景三个功能,虽然这些CPU/GPU也能跑,但或许用NPU功耗更低。
设备:华硕 ROG 幻16 air (GU605),CPU:Intel Core Ultra 9 185H
打开Intel官网中Ultra 9 185H的资料,其对NPU的描述如下:

注意最后一行,由于OpenVINO是Intel官方的推理框架,后续我们将用它来测试,OpenVINO显然是支持Ultra的NPU的,相关文档如下:https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/npu-device.html,可以看到Ultra中NPU的实际型号为NPU 3720
测试环境实用Win11,其自带NPU的驱动(Linux下则需要自行编译),OpenVINO使用pip方式安装,具体请参考官方文档,注意其并非所有安装方式都有NPU支持。
硬件属性
使用如下代码检测NPU,并打印其硬件属性:
import openvino as ov
import openvino.properties as ovp
print(f"{ov.__version__ = }")
core = ov.Core()
print(f"{core.available_devices = }")
DEVICE = "NPU"
if DEVICE in core.available_devices:
print(f"- {DEVICE} found")
supported_properties = core.get_property(DEVICE, ovp.supported_properties)
for p, w in supported_properties.items():
try:
print(f"{p:>40} ({w}) = {core.get_property(DEVICE, p)}")
except Exception as e:
print(f"{p:>40} ({w}):", e)
else:
print(f"- {DEVICE} not found")在我的设备上输出如下:
ov.__version__ = '2024.0.0-14509-34caeefd078-releases/2024/0'
core.available_devices = ['CPU', 'GPU.0', 'GPU.1', 'GPU.2', 'GPU.3', 'NPU']
- NPU found
AVAILABLE_DEVICES (RO) = ['3720']
CACHE_DIR (RO) =
CACHING_PROPERTIES (RO) = {'DEVICE_ARCHITECTURE': 'RW', 'NPU_COMPILATION_MODE_PARAMS': 'RW', 'NPU_DMA_ENGINES': 'RW', 'NPU_DPU_GROUPS': 'RW', 'NPU_COMPILATION_MODE': 'RW', 'NPU_DRIVER_VERSION': 'RW', 'NPU_COMPILER_TYPE': 'RW', 'NPU_USE_ELF_COMPILER_BACKEND': 'RW'}
DEVICE_ARCHITECTURE (RO) = 3720
DEVICE_ID (RW) =
DEVICE_UUID (RO) = <已打码>
ENABLE_CPU_PINNING (RW) = False
EXCLUSIVE_ASYNC_REQUESTS (RW) = False
FULL_DEVICE_NAME (RO) = Intel(R) AI Boost
INTERNAL_SUPPORTED_PROPERTIES (RO) = {'CACHING_PROPERTIES': 'RW'}
LOG_LEVEL (RW) = Level.NO
MODEL_PRIORITY (RW) = Priority.MEDIUM
NPU_BACKEND_NAME (RO) = LEVEL0
NPU_COMPILATION_MODE (RW) =
NPU_COMPILATION_MODE_PARAMS (RW) =
NPU_COMPILER_TYPE (RW) = DRIVER
NPU_DEVICE_ALLOC_MEM_SIZE (RO) = 0
NPU_DEVICE_TOTAL_MEM_SIZE (RO) = 33554432
NPU_DMA_ENGINES (RW) = -1
NPU_DPU_GROUPS (RW) = -1
NPU_DRIVER_VERSION (RO) = 1688
NPU_MAX_TILES (RW) = -1
NPU_PLATFORM (RW) = AUTO_DETECT
NPU_PRINT_PROFILING (RW) = NONE
NPU_PROFILING_OUTPUT_FILE (RW) =
NPU_PROFILING_TYPE (RW): Unable to convert function return value to a Python type! The signature was
(self: openvino._pyopenvino.Core, device_name: str, property: str) -> object
NPU_STEPPING (RW) = -1
NPU_USE_ELF_COMPILER_BACKEND (RW) = AUTO
NUM_STREAMS (RO) = 1
OPTIMAL_NUMBER_OF_INFER_REQUESTS (RO) = 1
OPTIMIZATION_CAPABILITIES (RO) = ['FP16', 'INT8', 'EXPORT_IMPORT']
PERFORMANCE_HINT (RW) = PerformanceMode.LATENCY
PERFORMANCE_HINT_NUM_REQUESTS (RW) = 1
PERF_COUNT (RW) = False
RANGE_FOR_ASYNC_INFER_REQUESTS (RO) = (1, 10, 1)
RANGE_FOR_STREAMS (RO) = (1, 4)
SUPPORTED_PROPERTIES (RO) = {'AVAILABLE_DEVICES': 'RO', 'CACHE_DIR': 'RO', 'CACHING_PROPERTIES': 'RO', 'DEVICE_ARCHITECTURE': 'RO', 'DEVICE_ID': 'RW', 'DEVICE_UUID': 'RO', 'ENABLE_CPU_PINNING': 'RW', 'EXCLUSIVE_ASYNC_REQUESTS': 'RW', 'FULL_DEVICE_NAME': 'RO', 'INTERNAL_SUPPORTED_PROPERTIES': 'RO', 'LOG_LEVEL': 'RW', 'MODEL_PRIORITY': 'RW', 'NPU_BACKEND_NAME': 'RO', 'NPU_COMPILATION_MODE': 'RW', 'NPU_COMPILATION_MODE_PARAMS': 'RW', 'NPU_COMPILER_TYPE': 'RW', 'NPU_DEVICE_ALLOC_MEM_SIZE': 'RO', 'NPU_DEVICE_TOTAL_MEM_SIZE': 'RO', 'NPU_DMA_ENGINES': 'RW', 'NPU_DPU_GROUPS': 'RW', 'NPU_DRIVER_VERSION': 'RO', 'NPU_MAX_TILES': 'RW', 'NPU_PLATFORM': 'RW', 'NPU_PRINT_PROFILING': 'RW', 'NPU_PROFILING_OUTPUT_FILE': 'RW', 'NPU_PROFILING_TYPE': 'RW', 'NPU_STEPPING': 'RW', 'NPU_USE_ELF_COMPILER_BACKEND': 'RW', 'NUM_STREAMS': 'RO', 'OPTIMAL_NUMBER_OF_INFER_REQUESTS': 'RO', 'OPTIMIZATION_CAPABILITIES': 'RO', 'PERFORMANCE_HINT': 'RW', 'PERFORMANCE_HINT_NUM_REQUESTS': 'RW', 'PERF_COUNT': 'RW', 'RANGE_FOR_ASYNC_INFER_REQUESTS': 'RO', 'RANGE_FOR_STREAMS': 'RO', 'SUPPORTED_PROPERTIES': 'RO'}ResNet-50 单batch推理测试
使用fp16精度,batchsize = 1,重复2000次推理,单次耗时如下:
avg latency = 3.462ms
根据估计的ResNet-50的计算量,其达到的roofline性能大致如下(不准确,仅预估):
RESNET50_M_FLOP = 8206.520 # approximate RESNET50_M_MEM_RW = 105.763 # approximate avg latency = 0.0034620463848114014 reached GFLOP/s: 2370.4246 reached GB/s: 30.5493
达到的fp16性能约为2.35 TFLOP/s,由于是bs=1的推理,离上限值应该还是有不小距离的
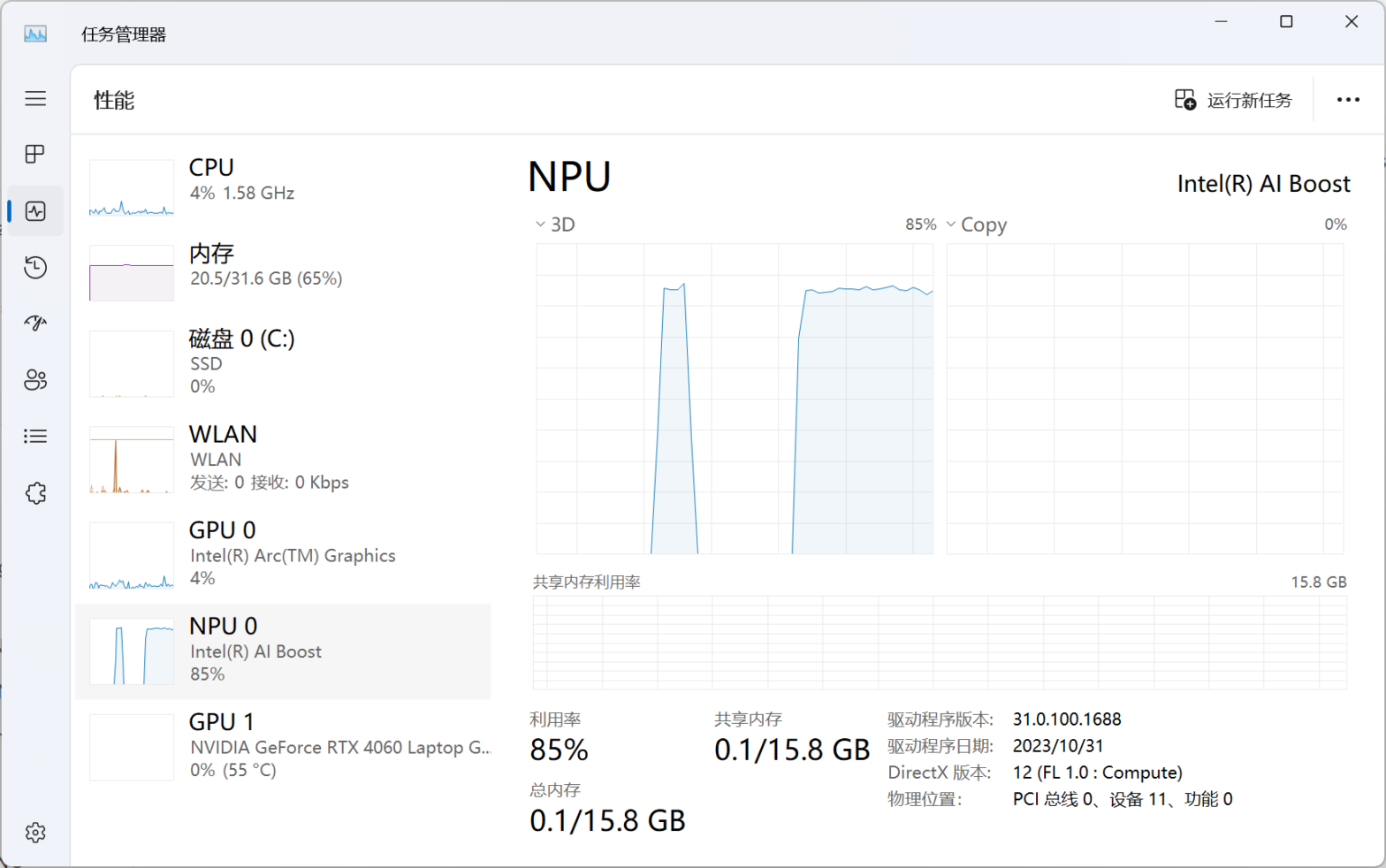
功耗的话,用HWInfo64可看到“System Agent Power”在推理时从4w左右增加到10w左右,即6w,不确定这其中是否都是NPU的功耗,否则这个能效表现其实一般。不过在打开全部的“Windows工作室效果”时,System Agent功耗仅上升了1~2w,此时任务管理器中NPU利用率约为46%
多模型Roofline测试
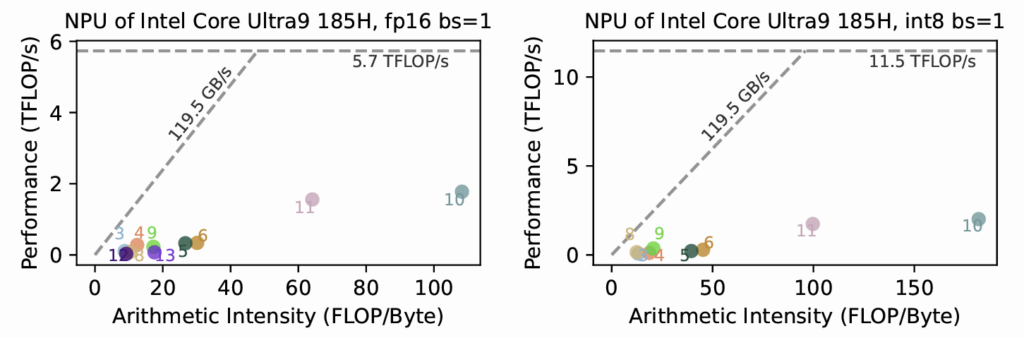
这是多个模型在其上的测试,达到的FLOP/s和内存带宽基于理论估计,模型列表如下,不存在则表示(在当时)尚无法成功运行。

可以看出,其优化程度较差,远远无法跑到理论性能fp16: 5.7 TFLOP/s, int8: 11.5TOP/s(计算方法:2048 fp16 MACs or 4096 int8 MACs per cycle @ 1.4GHz)。也有文章指出,其可能无法利用全部的内存带宽,具有远远更低的内存墙,但依然无法解释为何ResNet-34的性能也很低。
发表回复