论文全名:Benanza: Automatic μBenchmark Generation to Compute “Lower-bound” Latency and Inform Optimizations of Deep Learning Models on GPUs
原文链接:https://arxiv.org/pdf/1911.06922.pdf
这周在组会上介绍了这篇ML sys的论文,正好来写成一篇博客。这篇文章他是发表在IPDPS 2020上的,不算新,但其中分析总结的若干在GPU上的优化策略还是有一定参考性。同时本文也是本博客第一篇关于高性能计算(HPC)和深度学习系统(ML sys)的博客。
这篇文章设计了一种layer-level的profiling和analyze工具,叫做Benanza,它提出了一个“lower-bound” latency的概念,和实际测量的latency对比,用于分析深度学习推理框架的潜在优化空间。同时用BR(Benanza Ratio)表示优化程度(BR = lower-bound latency / measured latency),越接近1表示优化程度越高。
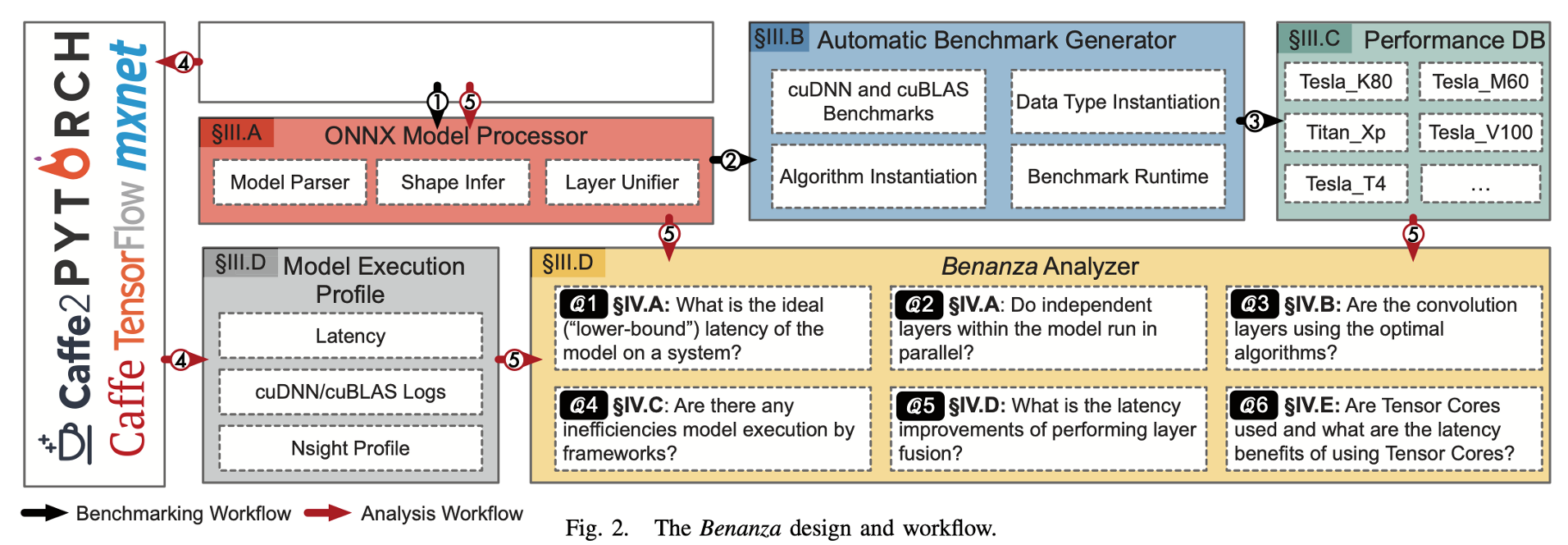
这个“lower-bound” latency是通过将原模型的每一个算子,都是用cudnn和cublas中最优的kernel去跑,所得到的时间。具体的将(结合下图),它的benchmark流程(下图黑色箭头)接受一个ONNX格式的模型,解析并找出一系列不重复的算子(包括算子类型和shape),然后在cudnn和cublas中找到最优的实现,并将结果存入benchmark数据库。之后它的analyze流程(下图红色箭头)会首先让这个模型在某个框架中实际跑一下,记录其性能(measured latency),然后将其所有算子在benchmark数据库中的时间取出并求和,作为“lower-bound” latency,与measured latency做对比,反应其在各个角度的优化空间。
Benchmark流程
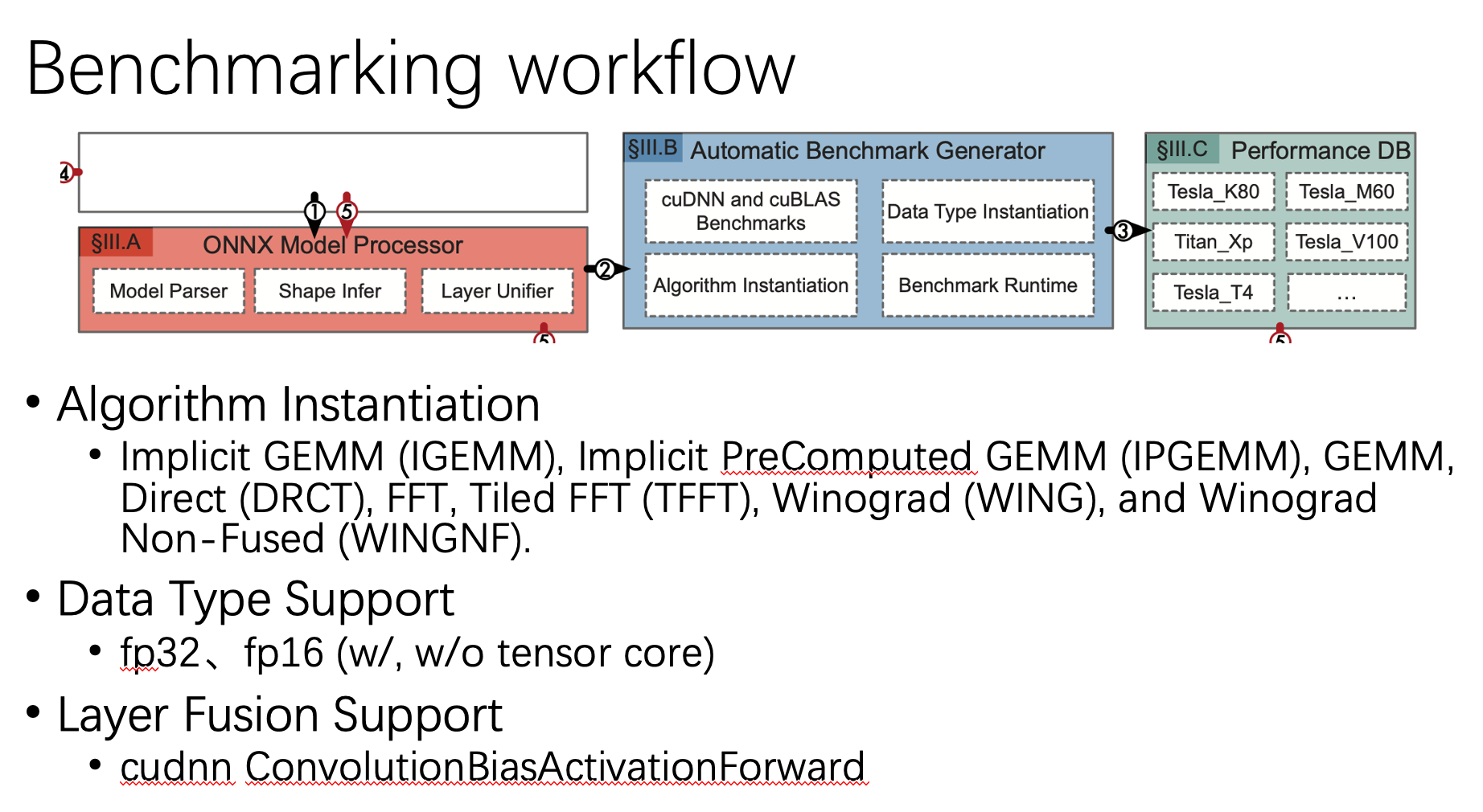
对于模型中的每个layer,它会生成一些列micro benchmark,同时也会涉及一些可能的优化手段,包括:
1. 算法选择:对于CNN中的卷积而言,会有很多种可用的算法,包括Implicit GEMM (IGEMM), Implicit PreComputed GEMM (IPGEMM), GEMM, Direct (DRCT), FFT, Tiled FFT (TFFT), Winograd (WING), and Winograd Non-Fused (WINGNF)等,Benanza会把他们都跑一遍,选择一个最优的。
2. 数据类型:Benanza跑了fp32和fp16下的对应kernel,对于fp16来讲,还分别跑了用和不用tensorcore的两种情况。
3. 算子融合:Benanza也做了算子融合的尝试,主要利用的是cudnn的ConvolutionBiasActivationForward API。
以上产生的micro benchmark中最后都会被存在工具的benchmark数据库中。
Analysis流程
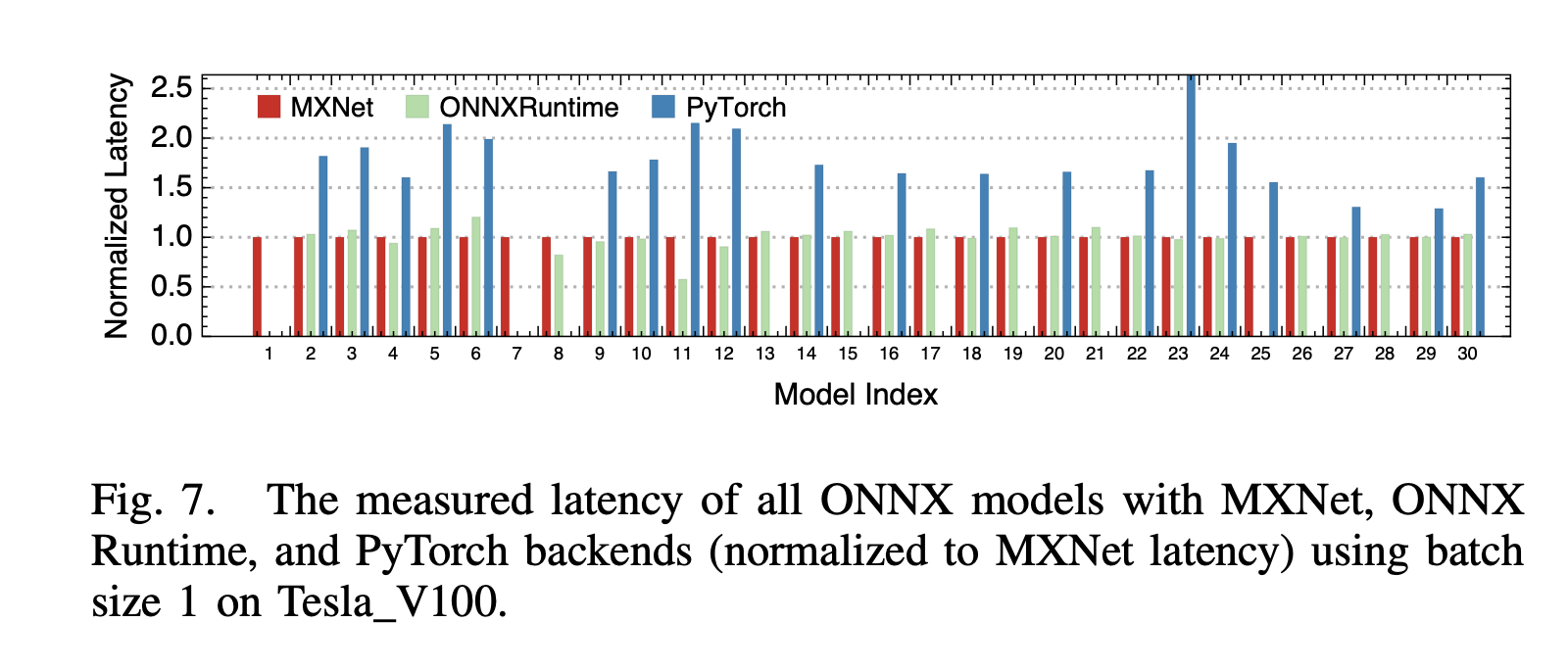
这里首先会让ONNX模型在一个现有的推理框架中运行,paper中跑了MXNet,ONNX Runtime和Pytorch,然后发现MXNet的性能普遍最好(见下图),后续也默认以MXNet的测量值作为measured latency。
接下来,结合各个优化点,对测量值和lower-bound latency进行比较:
1. 并行算子执行 vs 串行算子执行 的latency
对于一些模型,某些算子之间不存在数据依赖,是可以并行执行的,这里他假设并行情况下,算子可以以任意程度并行,最终整体的lower-bound latency是取单一的最长路径上的latency之和(下图红线):
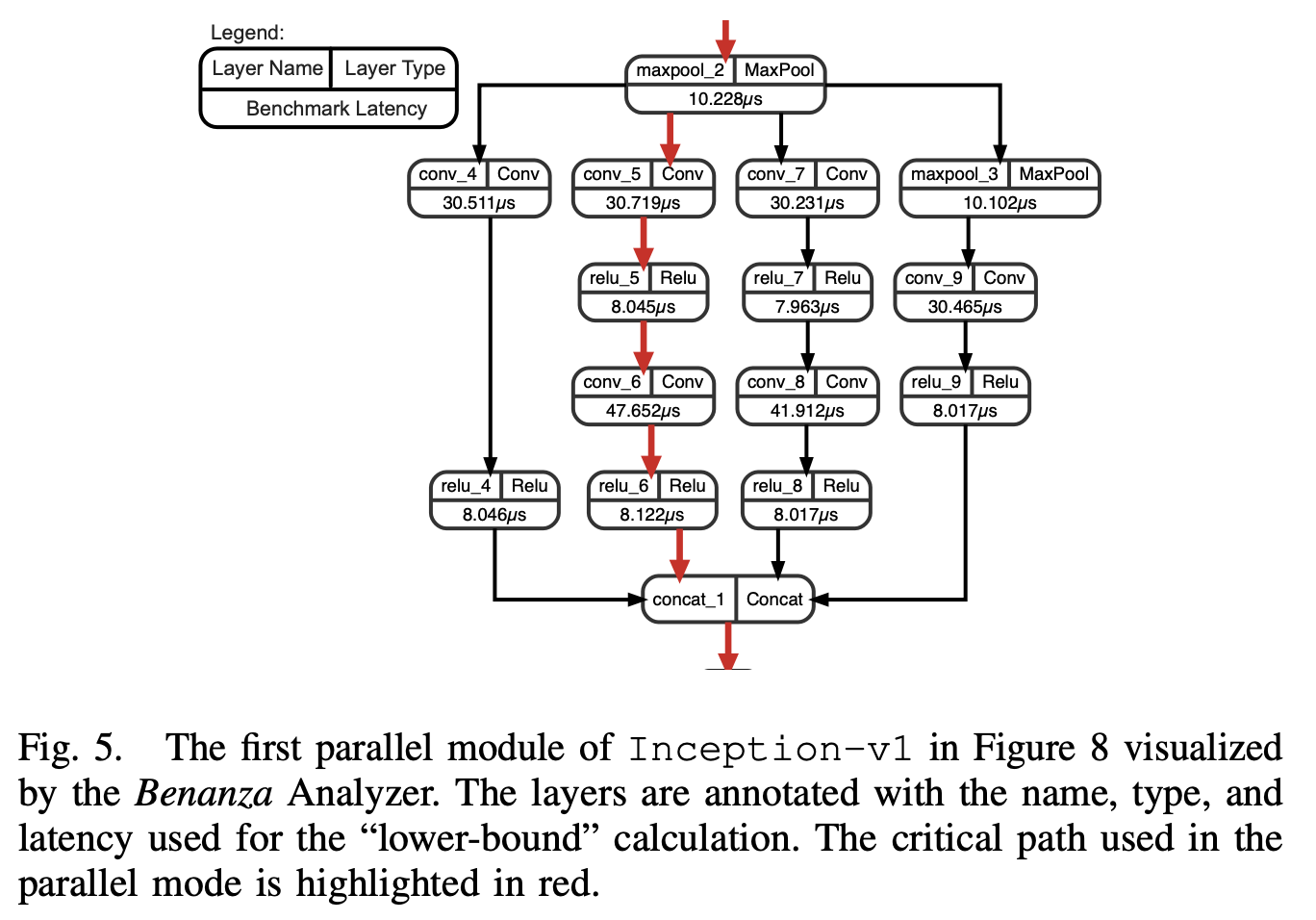
(这个我感觉不是很靠谱,现实中并行跑多个kernel肯定会影响latency,导致他这种算法的参考意义也不大)
并行和串行的对比如下:
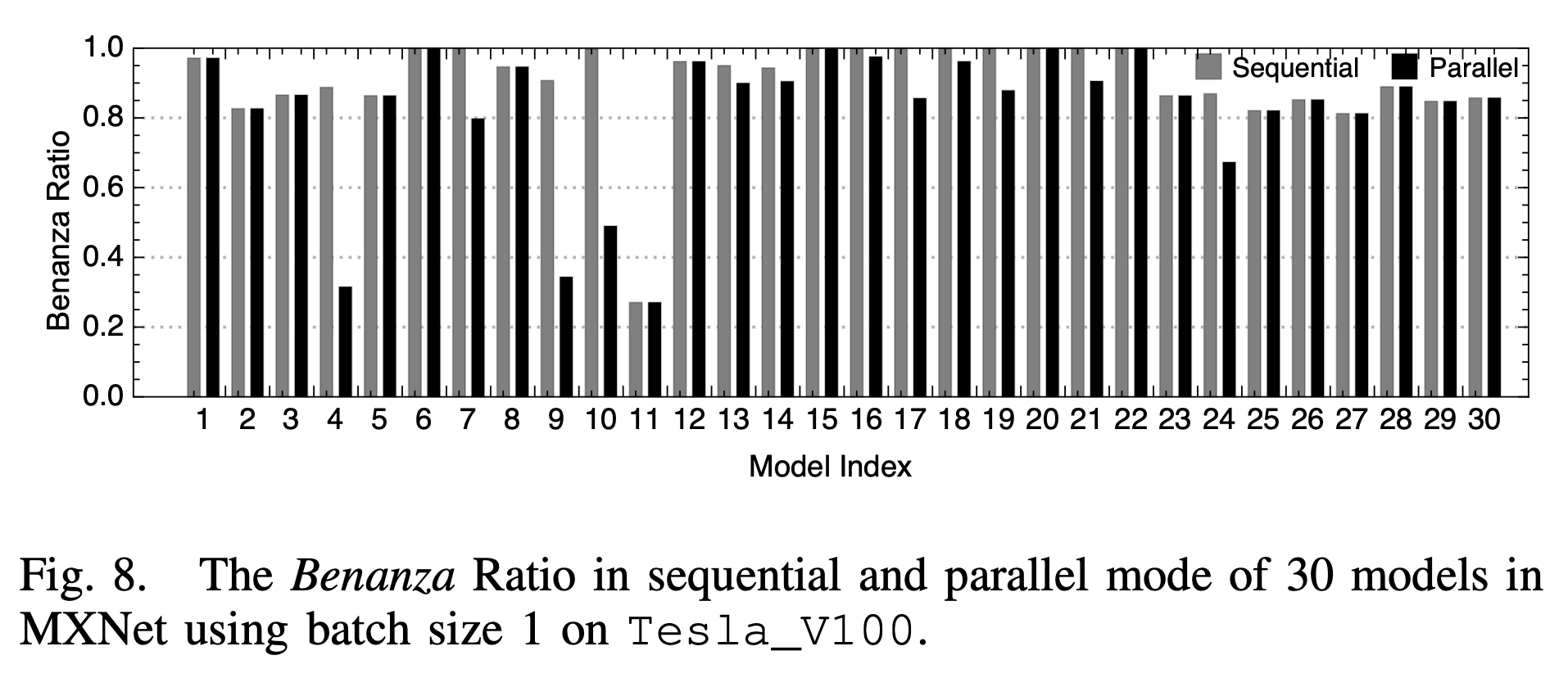
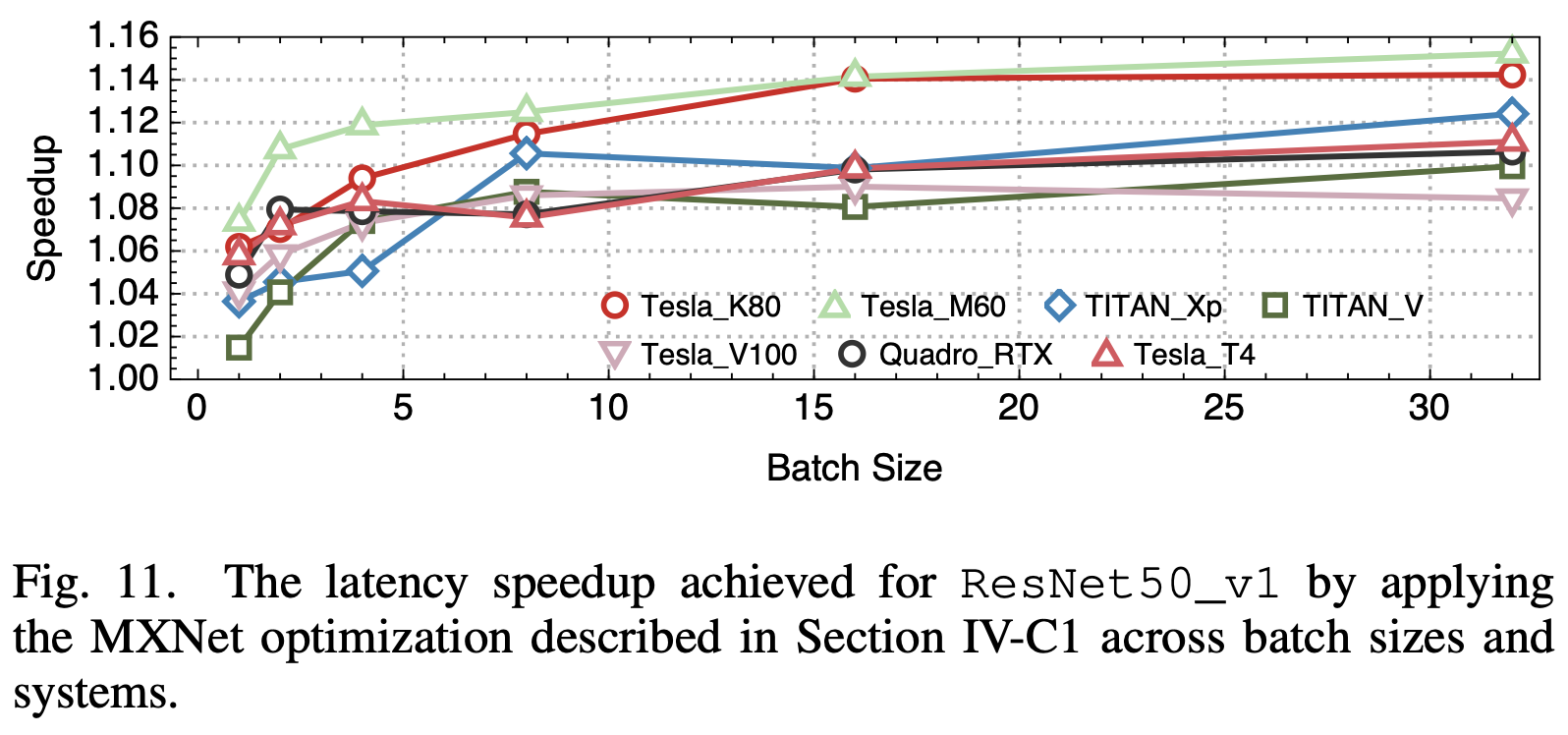
2. batch size和系统比较
他们对比了不同batch size下和在不同的架构的Nvidia GPU上的性能,他们观察到的比较有趣的一点是,系统的优化程度上:较新的架构 > 最新的架构 >> 旧架构。
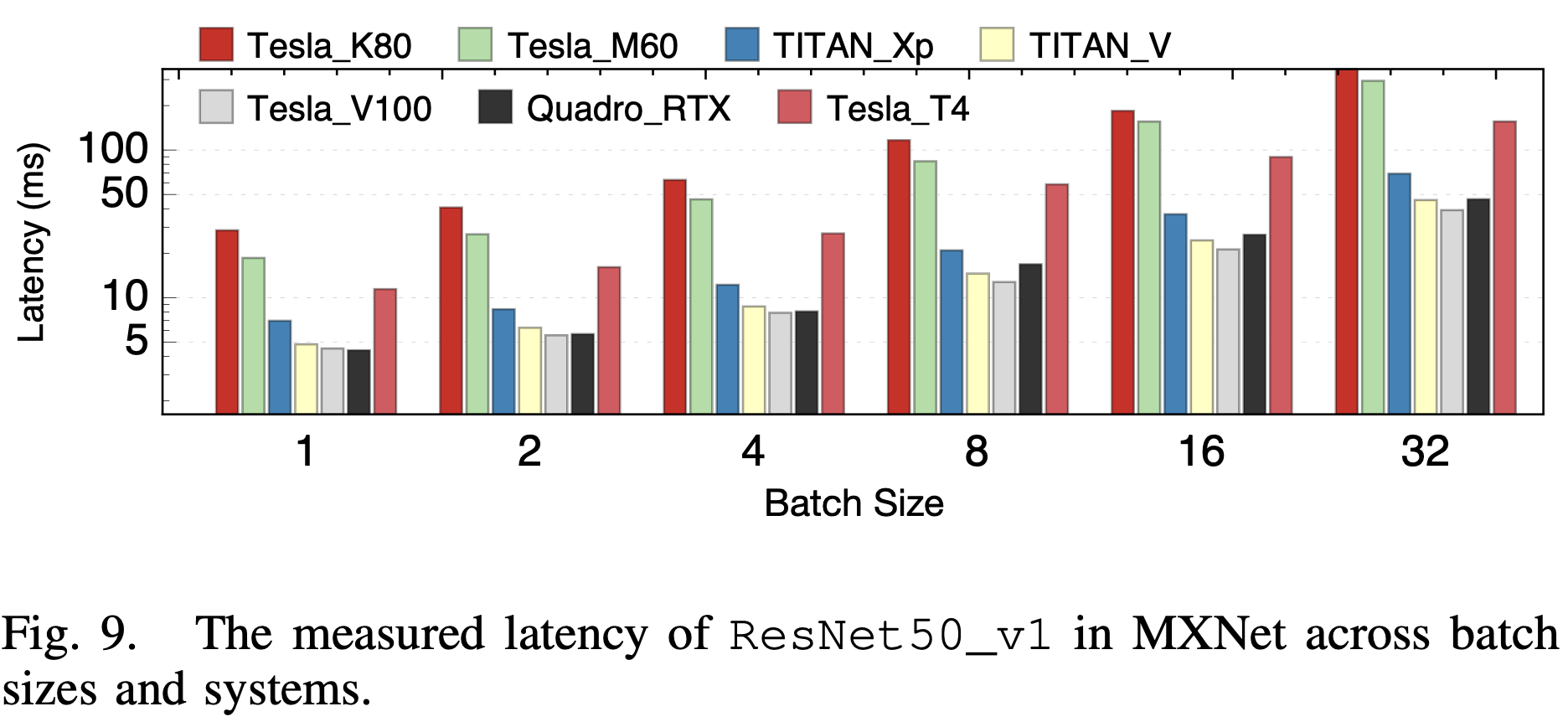
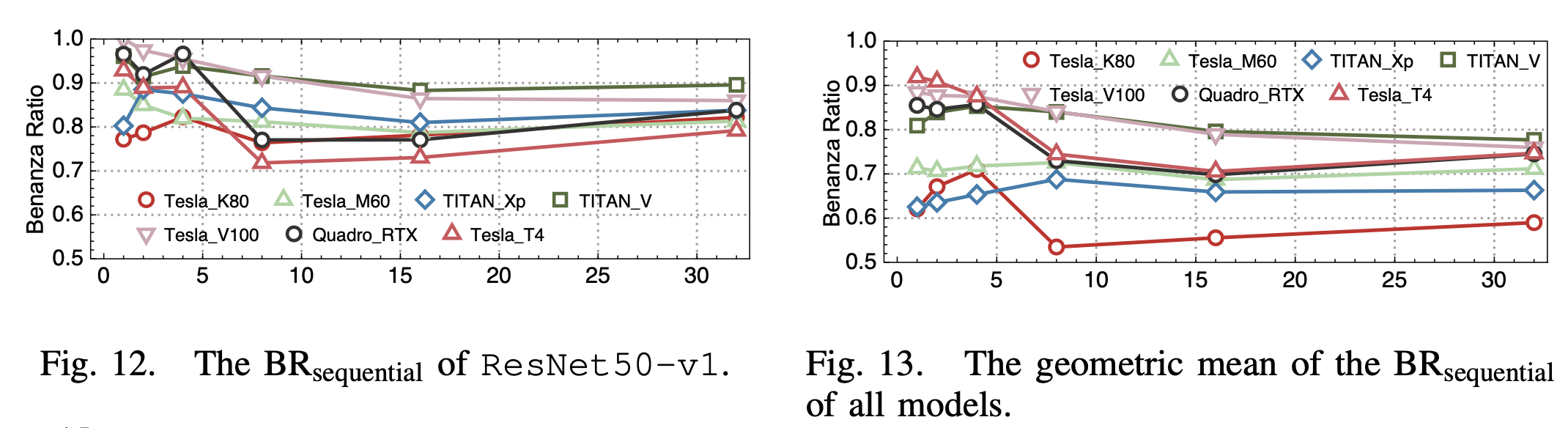
3. 卷积算法选择
前面提到,卷积算法有很多种,会有不同的性能特性,比如winograd算法能2~3倍的降低运算量,不同算法的访存特性也会不同。他们对比了框架所选择的卷积算法和最有的卷积算法,发现框架的选择并不一定是最优的:
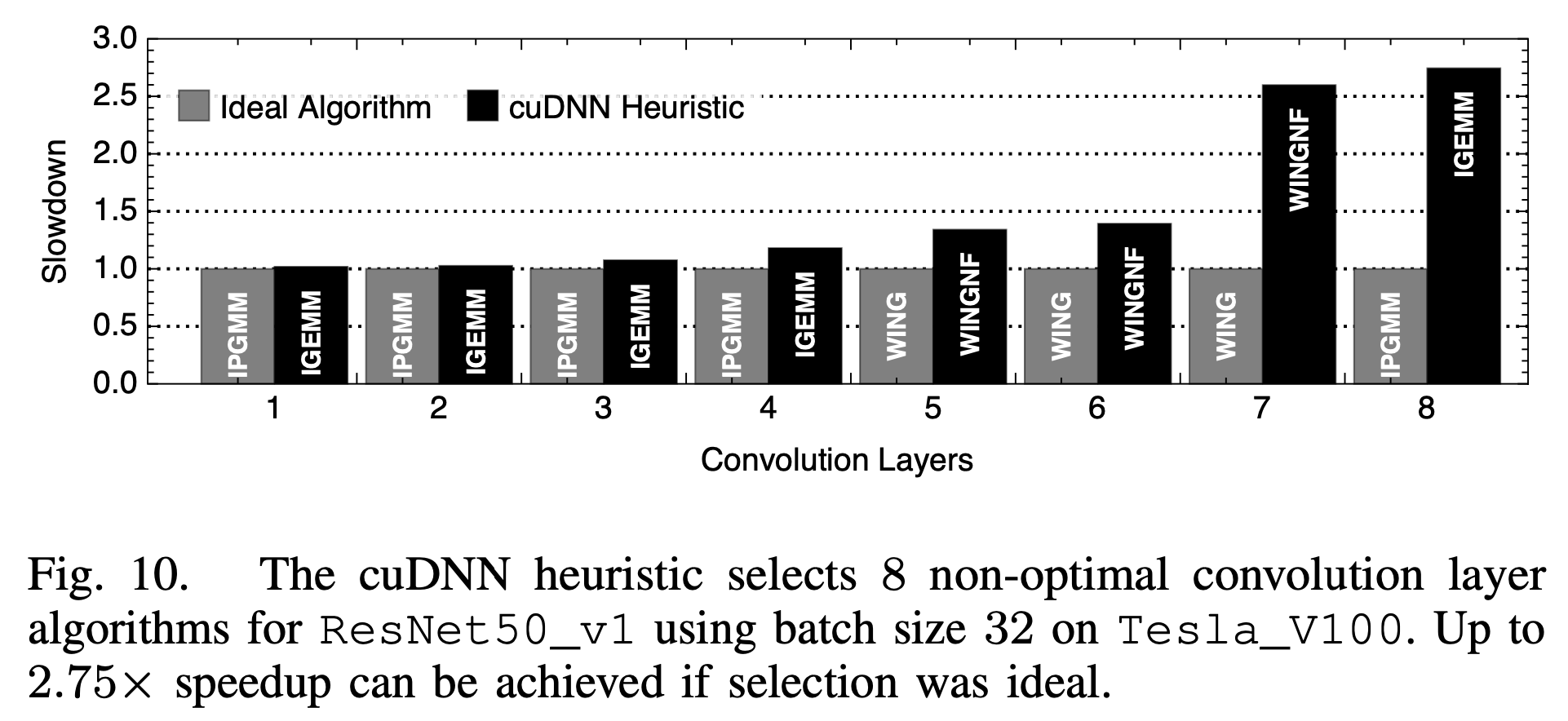
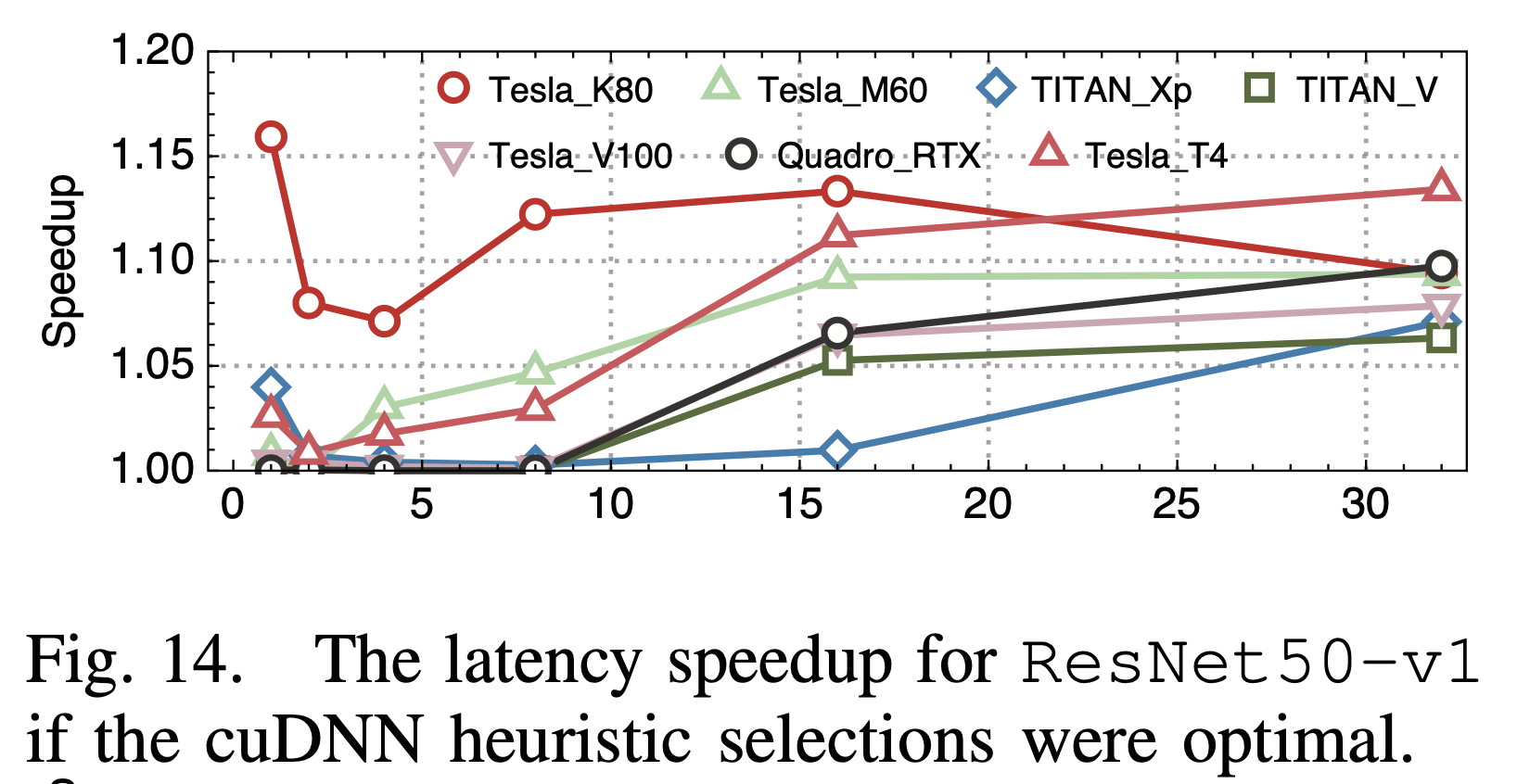
框架中一般都是通过cudnn的GetConvolutionForwardAlgorithm API来选择卷积算法,其本身是一个启发式的算法,相比实测,自然可能不是最优的。
4. 框架本身的开销
这里他们发现并优化了一些框架中不高效的地方,包括MXNet ONNX Model Loader中不必要的 image_2d_pad_constant_kernel,和PyTorch cuDNN Wrapper中不必要的 cudaStreamWaitEvent。
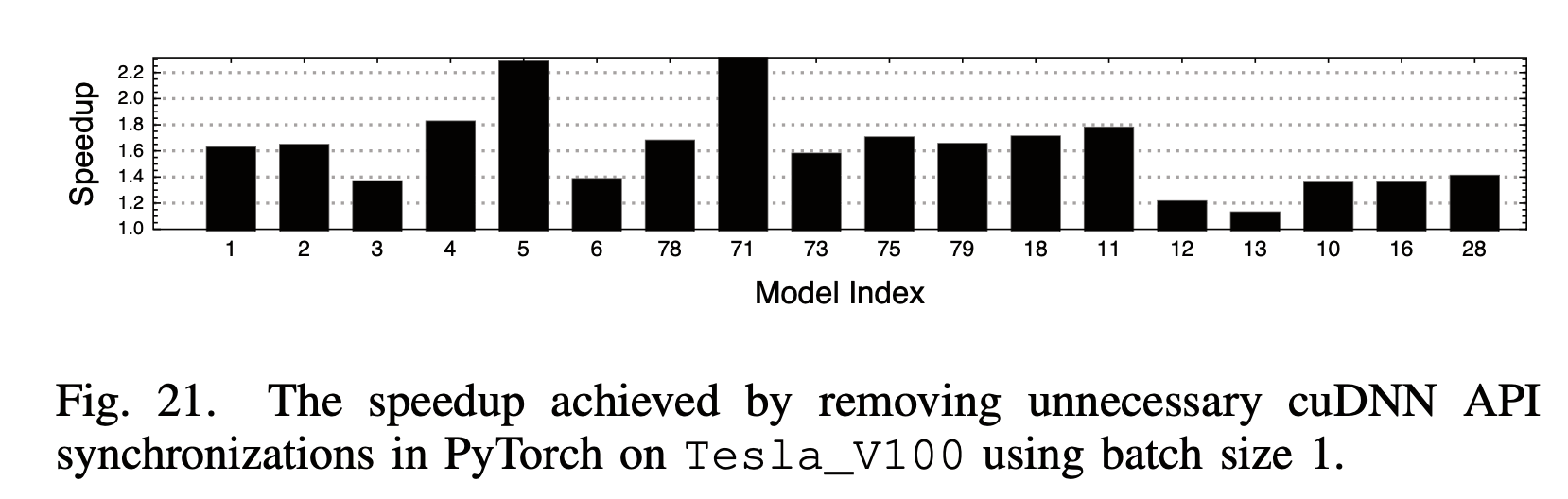
5. 算子融合
他们发现MXNet、ONNX Runtime和PyTorch进行推理时都没有做算子融合,而它们假设在ResNet50中做了一个简单的Conv -> Bias算子融合,可以得到一定的性能提升
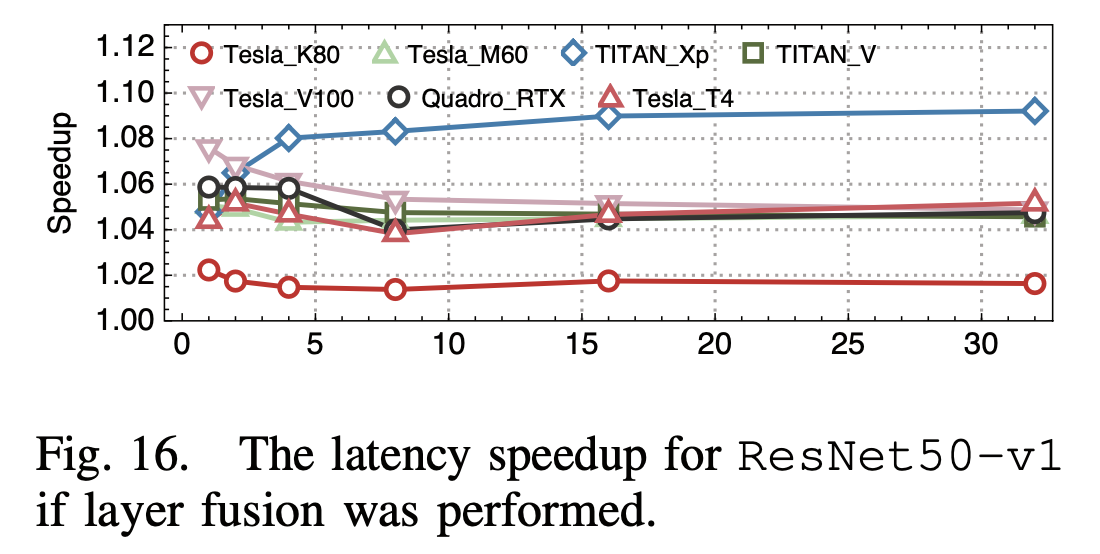
6. Tensor Core的利用
较新的Nvidia GPU上都有tensorcore,是专为深度学习优化的计算单元(主要是推理),支持fp16等较低的精度,可以高效的进行矩阵乘法等操作,FLOPS比常规单元高很多。因此如果推理能利用tensorcore,性能会有挺大的提升:
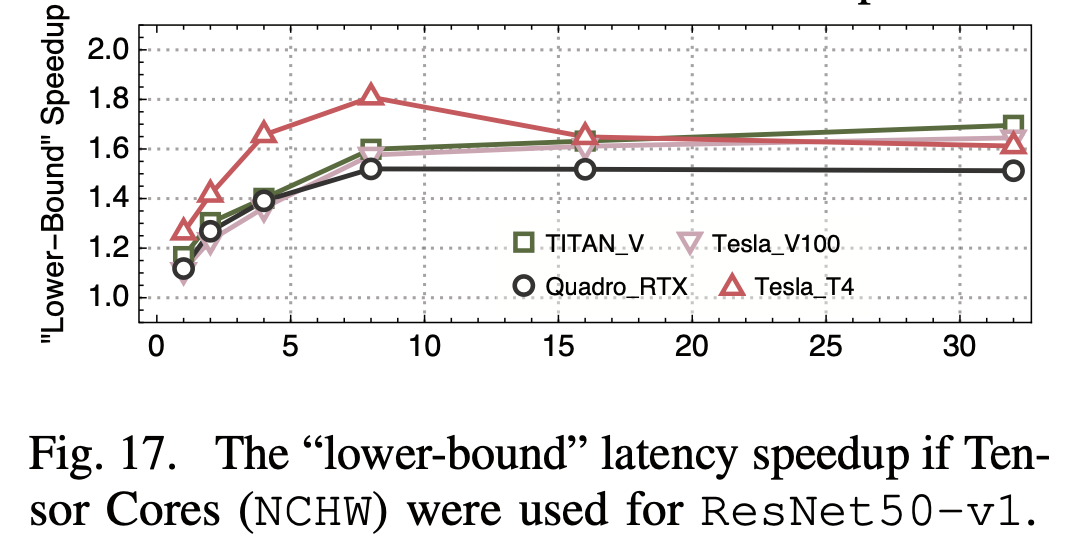
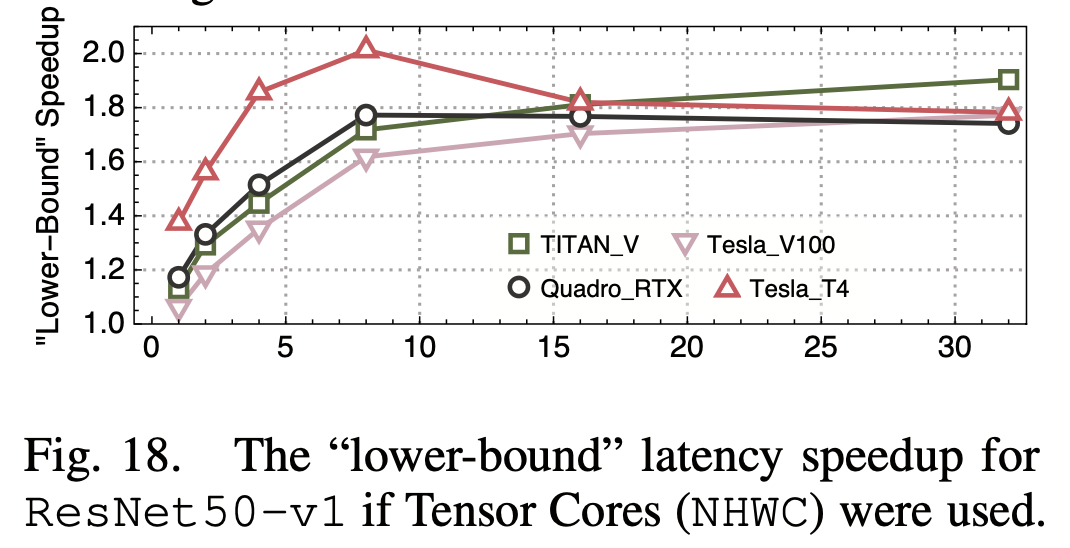
另外他们还发现NHWC格式要比NHWC数据排布格式快一些,这也是Nvidia所建议的格式。
最后,如果综合上述所有优化手段,带来的提升如下:
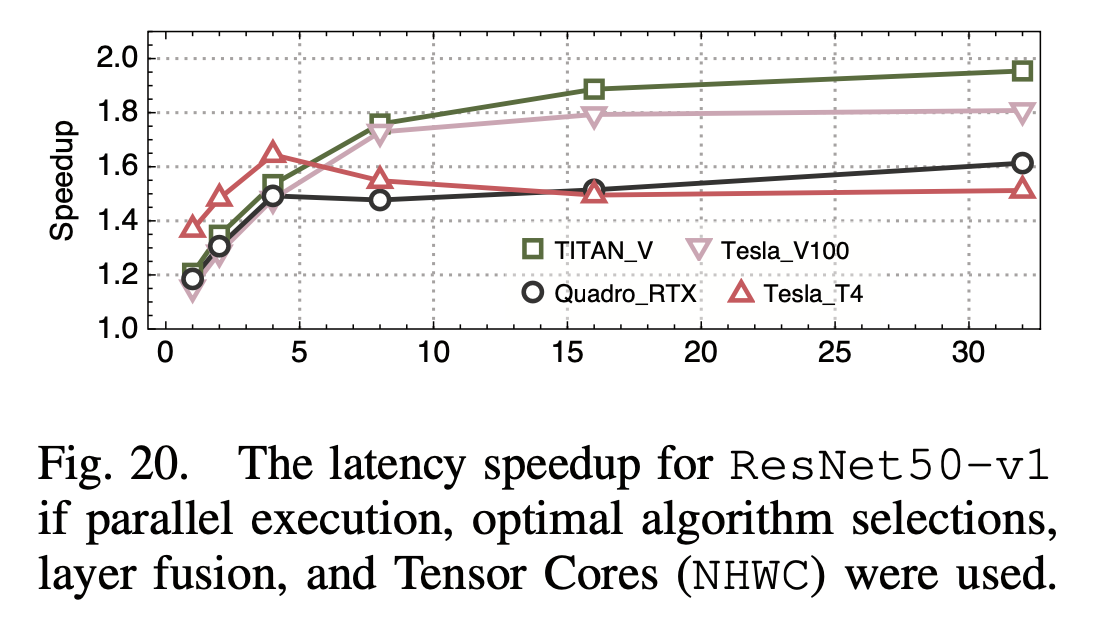
个人评价
这篇文章提出的分析工具还是挺有意思的,结合了模型的分析和实际的profiling,同时也算是总结了一遍目前在GPU推理框架上的常见的优化点。就他们所说,他们的主要贡献是在DL Benchmarking上提出了这套生成micro-benchmarks的方法,并在Performance Advising上提出了针对DL领域的优化指导。
但是我个人还是对他们的工作有一些疑问,首先他们只在MXNet、ONNX Runtime和Pytorch上进行了推理性能的实测,但这些框架并不是目前认为的最高效的推理框架。比如在Nvidia GPU上,tensorrt显然是更加高效的,也是目前工业级部署常用的运行时。对于tensorrt而言,文章中很多优化操作都是倍实现了的,甚至要比文章中还要多和好,比如tensorrt能进行比较好的算子融合,也会选择最优的卷积算法,更不用说对于自家tensorcore的支持。如果用了tensorrt作为实测的框架,可能就测不出什么优化空间了,甚至比他的“lower-bound” latency还要好都是有可能的。当然对于学术界在Nvidia tensorrt上确实也没什么可优化的了,不可能卷的过Nvidia自己,因此他这套方案对于其他运行时,乃至于迁移到其他的GPU、DLA等平台,还是有他的意义的。
另外文章中对于“并行执行算子”的优化空间的计算比较草率,上文也有提到。
发表回复